My thanks to Justin Parisi (@nfsdudeabides), Glenn Sizemore (@glnsize), and even Andrew Sullivan (@andrew_ntap, who wasn’t there) for allowing me to participate in Episode 30, in which I discuss NPSaaS (from my last post) among other topics. It was a blast!
NPS-as-a-Service: The perfect middle ground for the DataFabric vision?
 Everyone pondering the use of hyperscalar cloud for devops deals with one major issue- how do get copies of the appropriate datasets in a place to take advantage of the rapid, automated provisioning available in cloud environments? For datasets of any size, copy-on-demand methodologies are too slow for the expectations set when speaking of devops, which imply a more “point-click-and-provision” capability.
Everyone pondering the use of hyperscalar cloud for devops deals with one major issue- how do get copies of the appropriate datasets in a place to take advantage of the rapid, automated provisioning available in cloud environments? For datasets of any size, copy-on-demand methodologies are too slow for the expectations set when speaking of devops, which imply a more “point-click-and-provision” capability.
NetApp has previously provided two answers to this problem: Cloud ONTAP and NetApp Private Storage.
Cloud OnTAP represents an on-demand Clustered ONTAP instance within the Amazon EC2/EBS (and now Azure), that you can spin-up and spin-down. This is really handy, but can get expensive if you want the data to be constantly updated with data from on-prem storage, since the cloud instance must always be up and consuming resources. Further, some datasets could have custody requirements that prevent them from physically residing on public cloud infrastructures.
NetApp Private Storage addresses both of these problems. It takes customer purchased NetApp storage that is located at a datacenter physically close to the hyperscaler, and connects that storage at the lowest possible latency to the hyperscaler’s compute layer. The datasets remain on customer-owned equipment, and the benefits of elastic compute can be enjoyed. Of course, the obvious downside to this is the requirement of capital expenditure- the customer must purchase the storage (or at least lease it). Also, the customer must maintain contracts with the co-location site housing the storage, and do all the work to maintain the various connections from the AWS VPC through the Direct Connect, and from the customer datacenter to the co-location site. It’s a lot of moving parts to manage. Further- there’s no way to get started “small”; it’s all or nothing.
But wait! There’s a NEW OFFERING that solves ALL of these problems, and it’s called “NPSaaS”, or NetApp Private Storage as-a-Service.
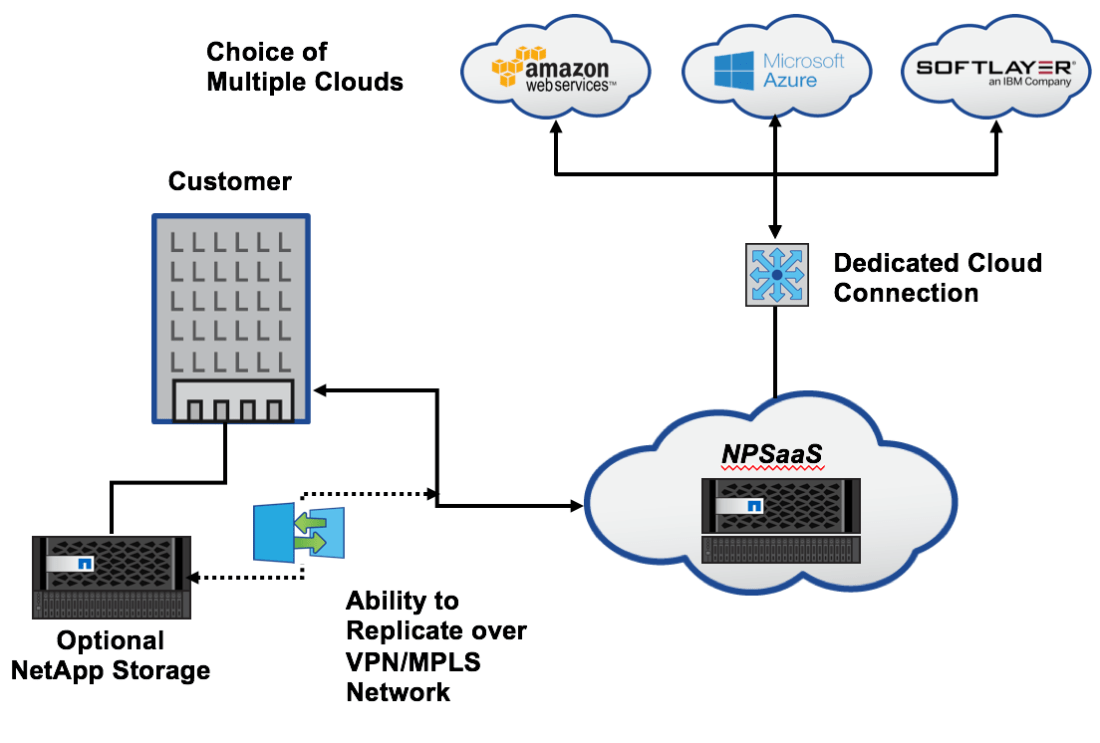
This offering, currently only available via Faction partners (but keep your eyes on this space) will provide all of the goodness of Netapp Private Storage, without most of the work and NONE of the capital expenditures. It’s not elastic per-se, but it is easily orderable and consumable in 1TB chunks, and in either yearly or month-to-month terms. Each customer gets their own Storage Virtual Machine (SVM), providing completely secure tenancy. It can provide a SnapMirror/SnapVault landing spot for datasets in your on-prem storage, ready to be cloned and connected to your EC2/Azure compute resources at a moment’s notice. You can of course simply provide empty storage at will to your cloud resources for production apps as well.
When you consume storage, you’ll be consuming chunks of 100mb/s throughput from storage to compute as well. You can purchase more throughput to compute if you want- not IOPS. You’ll get 50mb/s internet throughput as well. All network options are on the table of course, you can purchase as much as you’d like, both from storage->compute, and from storage->internet (or MPLS/Point-to-Point drop).
How is this achieved?
Faction has teamed up with NetApp to provide NetApp physical storage resources at the datacenters close to the hyperscalers, ready for use usually within 3-5 days of completion of paperwork, and it will be very simple to order. This means no additional co-lo contracts, no storage to buy, all you need to do is order your Amazon Direct Connect and VPC, and provide that information to Faction and you’ll be set in a few days to use your first 1TB of storage.
Once set up, you’ll be able to use NFS and iSCSI protocols at will. There are currently some limitations that prevent use of CIFS, but future offerings will provide that functionality as well.
From a storage performance perspective, we’re currently looking at FlashPool-accelerated SATA here. Again, future offerings may provide other options here, as well as dedicated hardware should the requirements dictate. But not yet. This level of storage performance provides the best $/GB/IOPS bang for the buck for the majority of storage IO needs for this use case; but if you’re looking for <1ms multi-100k IOPS here, “standard” NPS is what you’re looking for.
Faction also provides a SnapMirror/SnapVault-based backup into their own NetApp-based cloud environment, at additional charge. You could also purchase storage in multiple datacenters, SnapMirroring between them for regional redundancy to match the compute redundancy you enjoy from either AWS or Azure.
Note to remember: This offering is NOT a virtualized DR platform. You can’t take your VMFS or NFS datastores and replicate them into this storage with the idea of bringing them up in Amazon or Azure- that won’t work. So from a replication perspective, this would be more for devops capabilities to provide cloned datasets to your cloud VM’s.
Also, the management of the storage is almost completely performed by Faction on a service-ticket basis. This means (for now) that you won’t be messing with SnapMirror schedules, SnapShots, etc, which does put a little damper on the devops automation for cloning and attaching datasets, for instance. I’m sure this will be temporary as they iron out the wrinkles.
One other thing from a storage/volume provisioning perspective. Since we’re dealing with an on-demand Clustered OnTAP SVM instance here, Faction needs to carefully manage the ratio of FlexVols and capacity as the number of available FlexVols in a given cluster is not infinite. So you will originally get one volume, and you can’t get a second one until you consume/purchase 5TB for the first one, and so on. So if you want two volumes of 2TB each, you’ll need purchase 7TB (5TB for #1, and 2TB for #2). However, no reason you can’t have two 2TB LUNs in one volume- so this isn’t as big a constraint as it may at first seem, you just need to know this up front and design for it.
Drawbacks aside, this consumption model addresses the costs of a 100% utilized/persistent Cloud OnTAP instance, as well as the capital and contractual requirements of Netapp Private Storage. It’s certainly worth a look.
NetApp + SolidFire…or SolidFire + NetApp?

So what just happened?
First- we just saw AMAZING execution of an acquisition. No BS. No wavering. NetApp just GOT IT DONE, months ahead of schedule. This is right in-line with George Kurian’s reputation of excellent execution. This mitigated any doubt, any haziness, and gets everyone moving towards their strategic goals. When viewed against other tech mergers currently in motion, it gives customers and partners comfort to know that they’re not in limbo and can make decisions with confidence. (Of course, it’s a relatively small, all-cash deal- not a merger of behemoths).
Second -NetApp just got YOUNGER. Not younger in age, but younger in technical thought. SolidFire’s foundational architecture is based on scalable, commodity-hardware cloud storage, with extreme competency in OpenStack. The technology is completely different than OnTAP, and provides a platform for service providers that is extremely hard to match. OnTAP’s foundational architecture is based on purpose-built appliances that perform scalable enterprise data services, that now extend to hybrid cloud deployments. Two different markets. SolidFire’s platform went to market in 2010, 19 years after OnTAP was invented – and both were built to solve the problems of the day in the most efficient, scalable, and manageable way.
Third – NetApp either just made themselves more attractive to buyers, or LESS attractive, depending on how you look at it.
One could claim they’re more attractive now as their stock price is still relatively depressed, and they’re set up to attack the only storage markets that will exist in 5-10 years, those being the Enterprise/Hybrid Cloud market and the Service Provider/SaaS market. Anyone still focusing on SMB/MSE storage in 5-10 years will find nothing but the remnants of a market that has moved all of its data and applications to the cloud.
Alternatively, one could suggest a wait-and-see approach to the SolidFire acquisition, as well as the other major changes NetApp has made to its portfolio over the last year (AFF, AltaVault, cloud integration endeavors, as well as all the things it STOPPED doing). [Side note: with 16TB SSD drives coming, look for AFF to give competitors like Pure and xTremeIO some troubles.]
So let’s discuss what ISN’T going to happen.
There is NO WAY that NetApp is going to shove SolidFire into the OnTAP platform. Anyone who is putting that out there hasn’t done their homework to understand the foundational architectures of the VERY DIFFERENT two technologies. Also, what would possibly be gained by doing so? In contrast, Spinnaker had technology that could let OnTAP escape from its two-controller bifurcated storage boundaries. The plan from the beginning was to use the SpinFS goodness to create a non-disruptive, no-boundaries platform for scalable and holistic enterprise storage, with all the data services that entailed.
What could (and should) happen is that NetApp add some Data Fabric goodness into the SF product- perhaps this concept is what is confusing the self-described technorati in the web rags. NetApp re-wrote and opened up the LRSE (SnapMirror) technology so that it could move data among multiple platforms, so this wouldn’t be a deep integration, but rather an “edge” integration, and the same is being worked into the AltaVault and StorageGRID platforms to create a holistic and flexible data ecosystem that can meet any need conceivable.
While SolidFire could absolutely be used for enterprise storage, its natural market is the service provider who needs to simply plug and grow (or pull and shrink). Perhaps there could be a feature or two that the NetApp and SF development teams could share over coffee (I’ve heard that the FAS and FlashRay teams had such an event that resulted in a major improvement for AFF), but that can only be a good thing. However the integration of the two platforms isn’t in anyone’s interests, and everyone I’ve spoken to at NetApp both on and off the record are adamant that Netapp isn’t going to “OnTAP” the SolidFire platform.
SolidFire will likely continue to operate as a separate entity for quite a while, as sales groups to service providers are already distinct from the enterprise/commercial sales groups at NetApp. Since OnTAP knowledge won’t be able to be leveraged when dealing with SolidFire, I would expect that existing NetApp channel partners won’t be encouraged to start pushing the SF platform until they’ve demonstrated both SF and OpenStack chops. I would also expect the reverse to be true; while many of SolidFire’s partners are already NetApp partners, it’s unknown how many have Clustered OnTAP knowledge.
I don’t see this acquisition as a monumental event that has immediately demonstrable external impact to the industry, or either company. The benefits will become evident 12-18 months out and position NetApp for long-term success, viz-a-viz “flash in the pan” storage companies that will find their runway much shorter than expected in the 3-4 year timeframe. As usual, NetApp took the long view. Those who see this as a “hail-mary” to rescue NetApp from a “failed” flash play aren’t understanding the market dynamics at work. We won’t be able to measure the success of the SolidFire acquisition for a good 3-4 years; not because of any integration that’s required (like the Spinnaker deal), but because the bet is on how the market is changing and where it will be at that point – with this acquisition, NetApp is betting it will be the best-positioned to meet those needs.
Parse.com – R.I.P. 2016 (technically 2017)
Today we witnessed a major event in the evolution of cloud services.
In 2013, Facebook purchased a cloud API and data management service provider, Parse.com. This popular service served as the data repository and authentication/persistence management backend for over 600,000 applications. Parse.com provided a robust and predictably affordable set of functionalities that allowed the developers of these mobile and web applications to create sustainable business models without needing to invest in robust datacenter infrastructures. These developers built Parse’s API calls directly into their application source code, and this allowed for extremely rapid development and deployment of complex apps to a hungry mobile user base.
Today, less than three short years later, Facebook announced that Parse.com would be shuttered and gave their customers less than a year to move out.
From the outside, it’s hard to understand this decision. Facebook recently announced that they had crossed the $1B quarterly profit number for the first time, so it’s not reasonable to assume that the Parse group was bleeding the company dry. Certainly the internal economics of the service aren’t well known, so it’s possible that the service wasn’t making Facebook any, or possibly enough, money. There was no change in pricing that was attempted, and this announcement was rather sudden.
No matter the internal (and hidden) reason, this development provides active evidence of an extreme threat to those enterprises that choose to utilize cloud services not just for hosting of generic application workloads and data storage, but for specific offerings such as database services, analytics, authentication or messaging- things that can’t be easily moved or ported once internal applications reference these services’ specific API’s.
Why is this threat extreme?
Note that Facebook is making LOTS of money and STILL chose to shutter this service. Now, point your gaze at Amazon or Microsoft and see the litany of cloud services they are offering. Amazon isn’t just EC2 and S3 anymore- you’ve got Redshift and RDS among dozens of other API-based offerings that customers can simply tap into at will. It’s a given that EACH of these individual services will require groups of people to continue development, and provide customer support, and so each comes with it an ongoing and expensive overhead.
However, it’s NOT a given that each (or any) of these other individual services will provide the requisite profits to Amazon (or Microsoft, IBM, etc) that would prevent the service provider from simply changing their minds and focusing their efforts on more profitable services, leaving the users of the unprofitable service in the lurch. There’s also the very real dynamic of M&A, where the service provider can purchase a technology that would render the existing service (and its expensive overhead) redundant.
While it’s relatively simple to migrate OS-based server instances and disk/object-based data from one cloud provider to another (there are several tools and cloud offerings that can automate this), it’s another thing entirely to re-write internal applications that directly reference the APIs of these cloud-based data services, and replicate the data services’ functionality. Certainly there are well-documented design patterns that can abstract the API calls themselves, however migrating to a similar service given a pending service shutdown (as is faced today with Parse.com) requires the customer to hunt down another service that will provide almost identical functionality, and if that’s not possible, the customer will have to get (perhaps back) into the infrastucture game.
Regardless of how the situation is resolved, it forces the developer (and CIO) to re-think the entire business model of the application, as a service shuttering such as this can easily turn the economics of a business endeavor upside-down. This event should serve as a wake-up call for developers thinking of using such services, and force them to architect their apps up-front, utilizing multiple cloud data services simultaneously through API abstraction. Of course, this changes the economics up-front as well.
So for all you enterprise developers building your company’s apps and thinking about not just using services and storage in the cloud, but possibly porting your internal SQL and other databases to the service-based data services provided by the likes of Amazon, buyer beware. You’ve just been given a very recent, real-world example of what can happen when you not only outsource your IT infrastructure, but your very business MODEL, to the cloud. Perhaps there are some things better left to internal resources.
Information-235: Using decay models in a data infrastructure context
Information, like enriched uranium, doesn’t exist naturally. It is either harnessed or created by the fusion of three elements:
- Data
- People
- Processes
This is important to understand – many confuse data with information. Data by itself is meaningless, even if that data is created by the combination of other data sources, or rolled up into summarized data sets. The spark of information, or knowledge, occurs when a PERSON applies his/her personal analysis (process) to enable a timely decision or action.
Once that information has been created and used, its importance and relevance to the informed immediately begins to degrade – at a rate that is variable depending on the type of information it is.
This is not a new idea- there are more than a few academic and analytical papers that have been published that discuss models for predicting the rates of decay of information, and so I can thankfully leave the math for that to the mathematicians. However, the context of these academic papers is data analytics, and how to measure the reliability or relevance of datasets in creating new actionable information.
I believe that this decay construct can become a most valuable tool for the infrastructure architect as well, if we extend the decay metaphor a bit further.
Just as when you enrich a radioactive isotope, it transforms into something ELSE, when a radioactive isotope DECAYS, it decays into less radioactive ones, and sometimes even those isotopes decay further in a multi-step decay chain. We can see that same behavior with information and its related data.
Let’s take an example of a retail transaction. That transaction’s information is most important at the point of sale- there are hundreds of data points that gets fused together here, including credit card info/authorization, product SKUs, pricing, employee record, just think of everything you see on a receipt and multiply by x. That information is used during that day to figure the day’s sales, that week to figure some salesperson’s commission perhaps, that month to figure out how to manage inventory.
A subset of that transaction’s information will get used in combination with other transactions to create summarized information for the month, quarter, and year. The month and quarterly data will be discarded after a few years as well, leaving the yearly summaries.
So in time, that information that was so important and actionable day one becomes nothing but a faint memory, yet the FULL DATA SET on that transaction is likely going to be stored, in its entirety, SOMEWHERE. That somewhere, of course, we’ll call our Data Yucca Mountain.
What does this mean to the infrastructure architect?
If one can understand the data sets that create information, and understand the sets of information that get created from the datasets as well as “depleted” information (think data warehouses and analytics), then one should be able to construct the math to not only design the proper places for data to sit given a specific half-life, but to SIZE them correctly.
This model also gives the architect the angle to ask questions of the business users of information (and data), which will give him/her the “big picture” that allows them to align infrastructure with the true direction and operations of the business. Too often, infrastructure is run in a ‘generic’ way, and storage tiers are built by default rather than by design.
Building this model will take quite a bit of work, but it will go a long way towards ensuring alignment between the IT Infrastructure (or cloud) group and the business, and provide a much clearer ROI picture in the process.
The shifting dynamics of infrastructure
In my former role, I was the one who had the final word on what technologies our firm was to include in our integrated offerings to our clients. I spoke to dozens of technology manufacturers each month, evaluated their products in my lab, spoke to clients who used or evaluated the technologies, etc. Many of these hopefuls left empty-handed even though their technologies may have been quite exciting, even performing better than the standard-bearers in the markets they were trying to break into. If that market was the Enterprise Storage market, they had two strikes on them before ever coming to the plate, and I will discuss why.
Some may know that I’ve been a NetApp advocate for quite some time, but that’s NOT the reason the newer firms had a disadvantage. I have ALWAYS submitted that if someone else came to the table with the best demonstrable breadth and depth of feature/functionality/efficiency, with some proof of staying power, that would be the solution that I’d prefer to integrate and bring to my clients.
That’s not what I’m talking about here.
I’m talking about the market dynamics that present a real danger to today’s storage startups. I can’t look a client in the eye three years from now if I’ve recommended to them a product that is either gone, or subsumed into a black pit of a mega-conglomerate and de-emphasized. Even if there is a 25% risk of that happening, that’s more than zero and must be added to the product selection process.
Let’s discuss the dynamic. Please note that what follows are general statements, I’m well aware that of course it won’t go down 100% the way this flows, but I argue it doesn’t have to for the dynamic to still hold true.
The Storage market has a continuum that’s typically broken up into a few groups:
- Service Providers
- Large Enterprises
- Medium-sized Enterprises (MSE)
- Small-to-Medium sized Businesses (SMB)
- Startups
If you are starting a business today (or have done so in the past 2-3 years), the overwhelming odds are that you aren’t going to buy any infrastructure. Why should you? With MS or Google, you’ve got 50-75% of the functionality you need, you can SaaS most of the rest with other vendors (Salesforce, Netsuite, Box, DropBox, you name it). Even if you need servers, you’ve got the hyperscalers. So Startups can do whatever they want IT-wise in ways that simply couldn’t be done ten or twenty years ago.
Startups, of course, become SMBs, then MSEs, as they succeed and grow. Sure, some of them get bought by established, larger firms that have their own infrastructure, but over time that pressure to be hyper-responsive to compete with smaller competitors will push everyone in the bottom three segments – Startups, SMB, and MSE – to move to cloud.
Of course, “cloud” falls under the Service Provider moniker. So as the infrastructure market for the SMB and MSE buckets shrink, the data’s gotta live somewhere, right?
Almost EVERY Storage startup first needs to establish a beachhead in SMB/MSE – that’s because Large Enterprises won’t give any of them the time of day until they’ve got a solid, stable, and reference-able customer base. This means that all of these storage startups (and more pop up every week it seems) are fighting over a market segment that is shrinking before our very eyes and will continue to shrink at an accelerating rate as the startups (using all cloud) of today grow into the SMB/MSE’s of tomorrow, and the current SMB/MSE’s transition to cloud in order to compete with them. Only when they transform into Larger/Medium Enterprises will these folks have the need for any significant storage infrastructure, especially as they’ve likely optimized their organization and processes to use cloud resources for most everything IT. Note, we’re talking about a few years down the road here, but this movement is real.
What of the other side of the market continuum? Large Enterprise, and Service Providers?
If the above dynamic holds true, Large Enterprise will, despite some leveraging of the cloud, still maintain a sizable, if not expanding, on-premises infrastructure. What would have been hyper-growth of on-prem storage may now only be logarithmic growth. But Large Enterprises are still buying large storage systems from the large storage vendors in large quantities, despite what how the trade rags tech blogs opine on the market. As this segment of the market is hesitant to deploy startup technologies, and has established relationships with the existing/established “big 5” storage vendors, there’s not much of a chance for others to break in- you’ll see mostly the “big 5” trading market share of this back and forth (which presents its own problems from a growth perspective to the “big 5”, that’s another story).
The Service Providers, however, are seeing storage growth at accelerating rates never before seen in the history of IT, and that acceleration will itself increase as the SMB/MSEs flock to the cloud and abandon infrastructure. Most of the storage startups won’t get to see much if any of that business, as they’re going to be too busy picking through the remains of what was once the SMB/MSE market they were architected to serve. THIS segment represents the real growth opportunity for the “big 5”- finding ways to leverage their platforms in physical and virtual form to support and sell into this Service Provider market segment.
So if you look at the choices made by the big storage companies (NetApp included), I believe you see a recognition of this dynamic and where their companies are going to succeed long-term, rather than solving yesterday’s problems cheaper or faster.
This dynamic is what gives me pause when evaluating today’s storage startups. Don’t get me wrong, the tech in most cases is amazing, and there are definitely things they do very, very well. The difference between these startups and the storage startups of 20 years ago is that the former startups had the TIME to develop their enterprise cred. These startups do not have that luxury, as they will need to establish that cred before the clock runs out on the SMB/MSE testing ground.
Netapp All-Flash FAS (AFF) – What does this mean?
A bunch of my contemporaries have published excellent technical blogs on NetApp’s recent release of their All-Flash FAS systems and simultaneous massive reduction in the acquisition and support prices of those same systems. I’ll pop those on my blog later.
So there’s great new info on how great these platforms perform, and how their costs are now in-line (or better) than competitors who have been flash-focused for a while now.
Assuming the performance is there (and based on performance numbers I’m seeing in real-world scenarios, it is), and those costs are well understood, does this development mean anything important to the storage or converged infrastructure market?
You betcha.
AFF now provides the SUPERSET of ALL STORAGE FEATURES offered by all the other flash storage providers, COMBINED.
Think about that for a second. Every protocol, file or block. Data movement across nodes. Data access across any node. Every data protection method desirable- no-penalty snapshot, Asynch replication, SYNCH replication, cross-site real-time replication with ZERO RTO/RPO failover, and vSphere 6/vVols support. Dedupe. Compression. Space-efficient cloning of volumes, luns, or files. Thin Provisioning. Non-disruptive, no-migration upgrades. Don’t forget the multi-tenancy features required by service providers- including the ability to magically and correctly route data to conflicting IP subnets using IP Spaces and broadcast domains. Add to that a myriad of ‘little’ features that allow enterprises to just say “yes, I can do it that way if I want”.
Now that NetApp (perhaps finally) has figured out that they can physically do flash as well as anyone else in the business within OnTAP, AND price it to sell, they can now RE-FOCUS the conversation on what’s been most important all along- the DATA – and the need to deliver and protect it in all sorts of form factors (datacenter, cloud, devOps, archive).
NetApp still has the alternative flash platforms (EF, and one day FlashRay) for those particular environments that don’t require all of the functionality that OnTAP excels at providing, so they’ve got their bases covered. I suspect most customers will opt for the features of OnTAP, in case they are needed later- especially if it doesn’t mean a significant price difference.
But the conversation about performance and price viz-a-viz other flash vendors is now OVER, and we can get back to solving problems. Which is where NetApp has been dominant for a long, long time.
On Change, Hysteria, and Continuity
Change is scary. Whether it’s a good or bad change, it’s ALWAYS a learning opportunity, whether the change happened to you directly, or to people you know or are just aware of.
Personally, I find myself at a point of very positive change, joining the esteemed firm Red8, LLC., after over 21 years of running the IT infrastructure VAR practice of another company. The scary part of this change is that I need to quickly improve my team-building and team-belonging skills; and re-learn how to utilize the resources available to me without abusing or mis-using them (and, of course, become a valuable resource to others!). My success in this new venture will directly correlate to my success in improving those skills. I’m excited beyond words.
Other changes are afoot at a technology partner I work with. Whether these changes are necessary, overdue, or unavoidable, are questions I’m going to think about for a while. This technology company (NetApp) has, in my opinion, the best technology on the market for solving the biggest problems on the minds of CIOs and CTOs today. They’re not going to come to customers and ask what they want to buy; they’re going to ask what the problems are and come back with a way to utilize their technology to solve those problems. That aligns perfectly well with how I approach customers, so it should be no surprise that I work with NetApp…a LOT.
This week there was a layoff at NetApp, and recently they’ve made some public-facing missteps that have nothing (really) to do with how they solve customer problems. There are market dynamics at work across the whole enterprise storage market – namely, the move to cloud and the emergence of many second/third tier storage vendors – and those dynamics are going to impact the biggest storage vendors most markedly. Again- this should be no surprise. These particular changes have appeared to catch NetApp more flat-footed than we’ve come to expect from them in the past.
NetApp, as it has historically done, has leaned right into the cloud dynamic, working to create solutions that will work with its existing technology, but allow for data to move from those platforms in and out of the public cloud providers. They are correct (IMO) in their guess that enterprises will NOT choose to put ALL of their data in the cloud, and will be forced to maintain at least some infrastructure to support their data management and production needs.
They are also guessing that customers will want their data in the cloud to look like and be managed like their data residing on-premise. This remains to be seen. Unstructured data has been moving to SaaS platforms like Box.com and Dropbox (among others) at accelerating rates. Further, making cloud storage look like it’s on a NetApp reminds me a bit of VTL technology, forcing a tape construct on large-capacity disks. There will be imperative use cases for this, but it’s not the most efficient way to use the cloud (it may be more functional in cases).
What has confused many CTOs (and technology providers) is the simultaneous rise of cloud…and FLASH. So, we’ve got one dynamic that is operationalizing unstructured (and some structured) data and getting it out of our administrative hands, and then we’ve got this other dynamic that’s geared towards our on-premise structured data, pushing the in-house application bottlenecks back up to the CPU and RAM where they belong. I can imagine having a single conversation with a CIO convincing him on the one hand to migrate his data and apps to the cloud to optimize budget and elasticity, and before it’s over perhaps discussing the benefits of moving his most demanding internal workloads to flash-based arrays which eliminates elasticity altogether. (Should it stay, or should it go??)
Now imagine you are a CTO at a technology company like NetApp, that solves many problems within the enterprise problem set, for a wide array (no pun intended) of customers. How are you supposed to set a solid technology direction when the industry’s futures arrows are all pointing different ways, and the arrows constantly move? As a market leader, you’re expected to be right on EVERY guess, and if you’re not, the trolls have a field day and the market kicks you in the tail. The “direction thing” (think GHWB’s “vision thing”) has contributed to the current NetApp malaise; the outside world sees multiple flash arrays, an object storage platform, Clustered OnTAP slowly (perhaps too slowly) replacing 7-mode systems, E-Series storage, a cloud-connected backup target product acquired from Riverbed…it’s hard to see a DIRECTION here. Internally, there have been multiple re-orgs upon re-orgs. But, what you DO see is the multiple moving arrows pointing multiple ways- and that’s the result of NetApp trying to solve the entire enterprise problem set in regards to data storage and management. If NetApp can be accused of fault, it can be that it perhaps tries to solve too MANY problems at once; you’re faced with keeping up with the changing nature of each problem, and sometimes the multiple problems force you into conflicting or multiple solution sets.
If you are a technology provider that only has one product- say, an all-flash array – you don’t have this direction problem, because your car doesn’t even have a steering wheel. It’s a train on a track, and you’d better hope that the track leads you to the promised land (yes, I’m aware I mixed metaphors there. Moving on..). Given the history of IT and technology invention and innovation, I wouldn’t make that bet. If you’re not leading the market to where you’re going, you’re only hoping it’s going to remain in your current direction. So the tier-2 and tier-3 vendors do not worry me too much long term, as they’re not solving problems that others haven’t solved already; sure, they’ll grab some market share in the mid-market, but the cloud dynamic is going to impact them just as hard as the big storage vendors, and they’ll be hard pressed to innovate into that dynamic. Combine that with the impact of newer, radically different non-volatile media already hitting early adopters and I believe we’ll get a thinning of that herd over the next few years.
So sure, this week has been a tough one for NetApp; and I feel horrible for those that lost their jobs. Given the rate at which other companies had been poaching NetApp’s talent prior to the layoff, I suspect any pain for these individuals will be short-lived. (I do find it amazing that trolls that bash NetApp celebrate when someone from NetApp leaves for another firm; if they liked them so much, why have they been bashing them before? Shouldn’t they now bash their new firm?)
I do want to caution those who say that NetApp has stopped innovating or is in decline. That could not be further from the truth. Clustered OnTAP is an evolution of OnTAP, not simply a new release. It’s not totally different, but it is… MORE. It’s uniquely positioned for the cloud-based, multi-tenant, CYA, do-everything-in-every-way workload that is being demanded of storage by large enterprise and service providers. Everyone else is still focused on solving yesterday’s problems faster (’cause it isn’t cheaper, folks). The technology portfolio has never been stronger. NetApp has historically been a year or more ahead of new problem sets- which certainly has negative revenue impacts as the market catches up (think iSCSI, Primary de-dupe, multi-protocol NAS, Multi-tenancy, vault-to-disk) – but count NetApp out at your own peril. People have been doing it since 1992 and NetApp has made fools of them all.
LACP aggregate on an Extreme Switch
Little helpful tidbit.
Setting up an LACP aggregate on an Extreme switch in the CLI is a piece of cake.
# enable sharing X grouping Y-Z lacp
Where X is the first or ‘master’ port in the aggregate, and Y-X are the ports that will be included in the aggregate. (Y should be the same as X in most cases).
Remember to save, and if your LACP partner on the other end is already configured, you’ll see that everything is up!
Great read re: Disruption
I encourage you to read this great (and short) article about disruption, and our mental models that allow it to happen to us:
