- (7:52AM MDT) Exciting day in Boulder, CO, where a bunch of folks from Solidfire (and Netapp) are going to be going through the state of their business, and announce all sorts of stuff. So, instead of trying to fit everything into tweets, I figured I’d do my best live blog impersonation! Stay here for updates, keep refreshing!

8:07am: Here we go! John Rollason, SolidFire Marketing director, takes (and sets the stage).
8:12am: #BringontheFuture is the hashtag of the day. Coming up is the keynote from Solidfire founder Dave Wright. This will be simulcast. I already see tweets about the new purchasing model, yet nobody’s ANNOUNCED anything. Oooh, Jeremiah Dooley’s going to do FIVE demos later. AND, George Kurian hits the stage at 5:15.

8:24am: John Rollason having a heck of a time trying to pronounce “Chautauqua”, which is where Solidfire will be taking folks for hiking tomorrow. Also- phones on “stun” please.
10:31am: Dave Wright in on stage. 
“One storage product cannot cover all the use cases for Flash in the datacenter”.
- EF- SPEED Demon. (One person sitting with me called it the “Ricky Bobby” flash storage.
- AFF- DATA SERVICES.
- SOLIDFIRE- SCALE.
This portfolio is now a $700M/year run rate. If you think Netapp is a laggard, you haven’t been paying attention!! The Analyst view of the AFA Market WAY over-estimated the impact of hybrid vs all-flash.
Per dave: “Netapp KILLING IT with all-flash adoption. Way Way ahead of analyst projections.” 33% of bookings are now all-flash. The adoption curve is so far ahead of what analysts projects, one wonders what they were thinking.
HA! graphic– headstone, RIP HYBRID STORAGE.
ANNOUNCEMENT : One platform, Multiple Consumption Models!
ANNOUNCEMENT: Element OS 9: FLUORINE
-VVOLS done right with per-vm QoS, New UI, VRF Multi-Tenant networking, 3x FC Performance and increase scale with 4 FC nodes now.
Functional AND sexy.
ANNOUNCEMENT: FULL FLEXPOD INTEGRATION! Converged Infrastructure – VMWare, OpenStack, one of the most compelling converged infrastructure offerings in the market.
ANNOUNCEMENT: SF19210 Appliance- 2x perf, 2x capacity, 30% lower $/GB, >1PB Effective Capacity & 1.5M IOPS in 15U.
“Appliance licensing is too rigid for advanced enterprises, agile datacenters”.
cost all up front, can’t be transferred, data reduction impose uncertainty/risk around actual cost of storage
ANNOUNCEMENT: SF FlashForward Storage
License Element OS SW on an Enterprise-wide basis. Based on Max Prov capacity
Purchase SF-cert’d HW nodes on a pass-thru cost basis
- Flexible – can purchase SW/HW separately – more efficient spend
- Efficient – No need to re-purchase when replacing, upgrading, consolidating – no stranded capacity
- Predictable – no sw cost penalty from low-efficiency workloads.
- Scalable – usage-based discount scheme, pass-through HW pricing – no unness sw or support costs increases as footprint expands
9:30am: Brendan Howe takes the stage to give a business update.
- Runs Emerging Products group @ Netapp.
- Reaching “extended customer communities”
- Scale (SF) vs. Data Services (AFF) vs. Speed (EF) (same story as before)
Opinion – perhaps this is TOO discrete of a model for positioning. Certainly SF is perfectly (perhaps MORE) appropriate for certain classic datacenter storage use cases than AFF at times. Anyone who sticks to this religiously is missing the point IMO.
- Operational Integration –
- Structured SF Business Unit
- GTM Specialists Team under James Whitmore
- Broad scale & pathway enablement
- Fully integrated shared services
- SolidFire office of the CTO (headed by CTO Val Bercovici)
- Must protect this investment
9:47am : James Whitmore takes the stage
- VP of Sales & Marketing
- 46% YoY bookings growth
- deal size >$240k avg
- 57% Net New Account acquisition YoY
- 218 Node largest single customer purchase (!!!!)
- >75% bookings through channel partners
- >30 countries
- 77% in the Americas
- Comcast, Walmart, Target, AT&T, TWC, Century Link
- 2 segments
- Transforming Digitals
- Native Digitals
- Cloud/Hosting Providers
- SaaS
- Cloud/Hosting
- Cable/Telco
- >80% increase in Enterprise Net-new account
- wins across every major vertical/use case
- finance, healthcase, SaaS, Energy, VMW/HyperV, Ora/SQL, VDI, Openstack
- customers truly committed to transforming their datacenters
- dominance in service provider market
- 20% YoY increase in # of SP’s, but a 3x+ increase in capacity!
- Very strong repeat business
- Channel Integration
- merge programs
- enable new-to-SF partners
- Leverage global distribution network
- SF Specialist Team
- Invest to accelerate growth
- Transfer product capability across org
- Direct specialists to high-growth segments and products
10:16am – Dave Cahill takes the stage.
IMPORTANT: THIN-PROVISIONING WILL CONSUME CAPACITY LICENSE at the provisioned amount, whether actually consumed or now.
QUESTION: Is capacity license consumed PRE-efficiency or POST-efficiency?
10:50am- Dan Berg & Jeremiah Dooley going to do geek stuff!

- Solidfire Products
- ElementOS
- Fluorine
- VVols, VASA2 built into the ElementOS SW – on a fully HA aware cluster!
- New UI
- Greater FC perf and scale
- Tagged default networks support
- VRF VLAN Support
- Platforms
- SF19210 – Highest density & performance
- Sub-millisecond latency – 100k IOPS
- 40-80TB effective cap
- Active IQ
- New- alerting/mgmt framework
- predictive cluster growth/capacity forecasting
- enhanced data granularity
- significant growth in hist data retention and ingest scale
- >80% leverage Active IQ
- Ecosystem Products
- Programmatic- powershell & sdks
- open source – docker/openstack/cloudstack
- Data Protection – VSS, Backup Apps, Snapshot offloading
- VMW- VCP, vRealize Suite
11:00am – Jeremiah Dooley – Principal Flash Architect
 VMWare Virtual Volumes and
VMWare Virtual Volumes and
Why Architecture Matters
VMFS – the best and worst thing to happen to storage
Nice slide, RIP VMFS.
VVol adoption is “slow” – takes time for partners/vendors to get their “goodies” into there
Since customers are virtualizing critical apps/DBs now, new feature/release adoption is a gen behind typically now
Getting customers in VVOLs
build policies throgh VASA2 like QOS
MIN/MAX/BURST
Move VM form vmfs into VVOLS – 8-line powershell script- ID/migrate/apply
Increase size of VVOLs- big difference from VMFS
GOAL: Do all the provisioning/remediation/growth without talking to the storage team.
Why Openstack?
- Agility – elasticity, instant provisioning, meet customer demand
- capex to opex model
- cluster deployment within an hour, given HW is ready
- Prod Development- self provisioning/ self service- dev can create/destroy environments
- Why not? lack of business cases (another guy) – so VMWare good fit for those
- Docker – openshift – docker/kubernets/docker storm
Imagine moving an 8-node cluster from one rack to another with NO DOWNTIME
12:00 – LUNCH, back at 1pm.
1:00 – Joel Reich takes the stage.

Joel is giving the ONTAP 9 feature set- including the easier application-specific deployments and high capacity flash.
ONTAP Cloud- many of Netapp’s larger customers using this for test/dev, some for Prod and they fail back on-prem.
ONTAP Select – Flexible capacity-based license, on white box equipment
Question: When the heck did White Box ever save anybody ANYthing
in the long run?
ANNOUNCEMENT: ONTAP Select with SolidFire Backend coming!
5:03pm- George Kurian – Closing Keynote
Enabling the Data Powered Digital Future
– Market Outlook- Enterprise IT spending has SLOWED –
ZING: EMC/Dell is a “Tweener” – not as vertically integrated as Oracle, they don’t do the whole stack
- Kurian- Netapp doesn’t need to be “first to market”.
- Q1 Market Share in AFA- Netapp 23%!! (IDC)
- New Netapp: Broad portfolio that addresses broad customer requirements.
- Netapp – “We protect and manage the world’s data”
- FY16 $5.5B, Cash $5.3B, total assets $10.0B
- 85% of shipment are clustered systems
- $1B free cash flow PER YEAR. Talk about stability.
- Pre-IPO,IPO,POst-IPO stories will be written in red ink
- 1) Pivot to Accelerate growth 2) Improve Productivity
- Work effectively to deliver results – Priorities, Integrated execution, Follow through
- Renew the Organization – Leadership, High Perf Culture, Talent
- 75% of CEOs will say biggest concern is not strategy but execution
- Incubate – pre-market (i.e. cloud), complete freedom of thinking, fail fast
- Grow – focus on biggest markets with biggest opp, inspect at district level, is the channel ready
- Globalize – mainstream GTM through every pathway possible
- Harvest – prepare for end of life, use revs to fund new businesses
- $700M+ AFA Annual Run Rate
- 80% YoY unit growth cDOT, 30% e-series YoY Unit growth
- 185% AFA YoY rev growth
- Transforming Netapp
- remove clutter 20 years of unmanaged growth
- focus on the best ideas
- “velocity offerings” – preconfigured offerings
- fine tune GTM model
- Shared services
- Close
- Fundamental change
- Good progress and accelerating momentum – more work needed
- Strong foundation
- Uniquely positioned to help clients navigate the changing landscape.
That’s it from Boulder, CO! Off to one of the three dinners that Netapp Solidfire have set up for the crowd tonight!

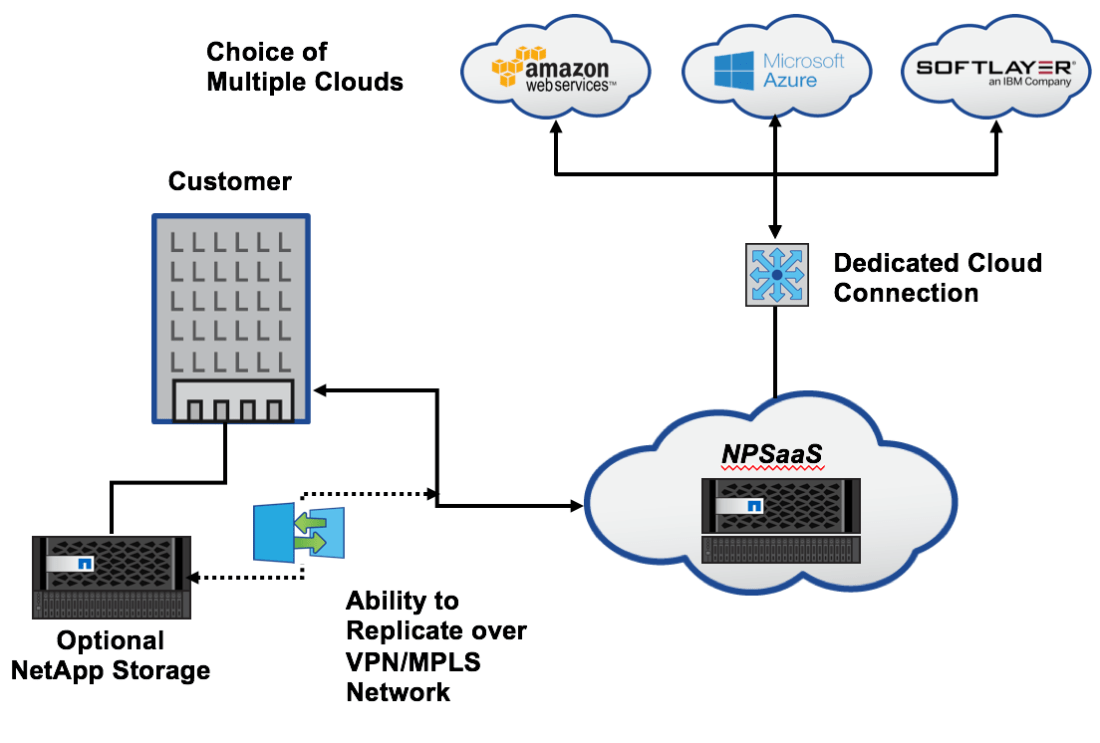
 Everyone pondering the use of hyperscalar cloud for devops deals with one major issue- how do get copies of the appropriate datasets in a place to take advantage of the rapid, automated provisioning available in cloud environments? For datasets of any size, copy-on-demand methodologies are too slow for the expectations set when speaking of devops, which imply a more “point-click-and-provision” capability.
Everyone pondering the use of hyperscalar cloud for devops deals with one major issue- how do get copies of the appropriate datasets in a place to take advantage of the rapid, automated provisioning available in cloud environments? For datasets of any size, copy-on-demand methodologies are too slow for the expectations set when speaking of devops, which imply a more “point-click-and-provision” capability.