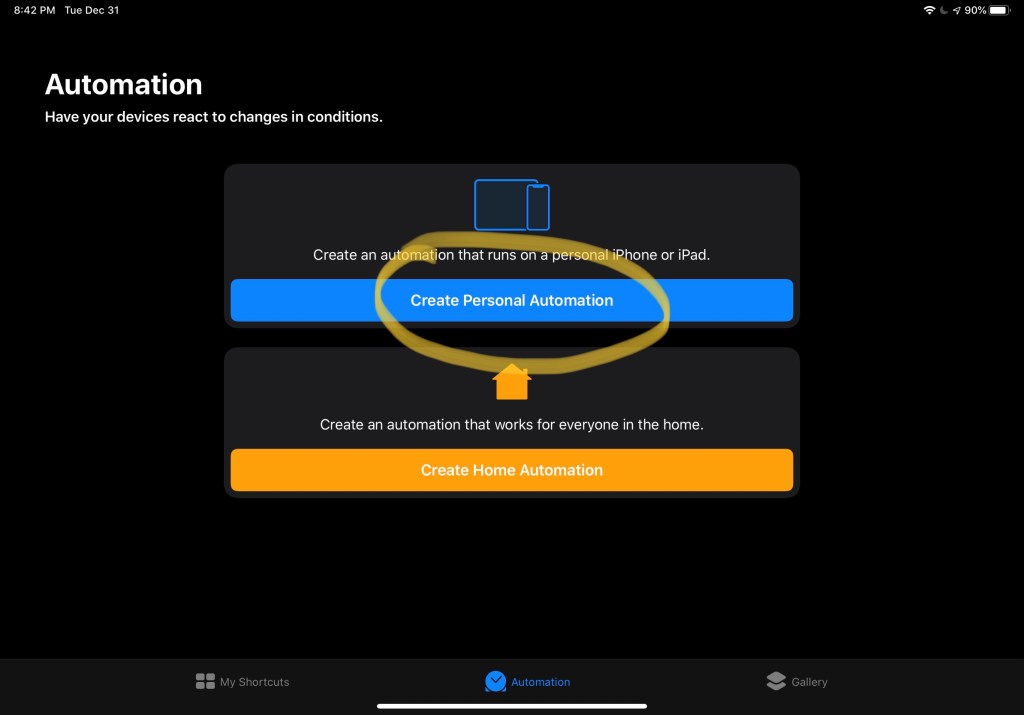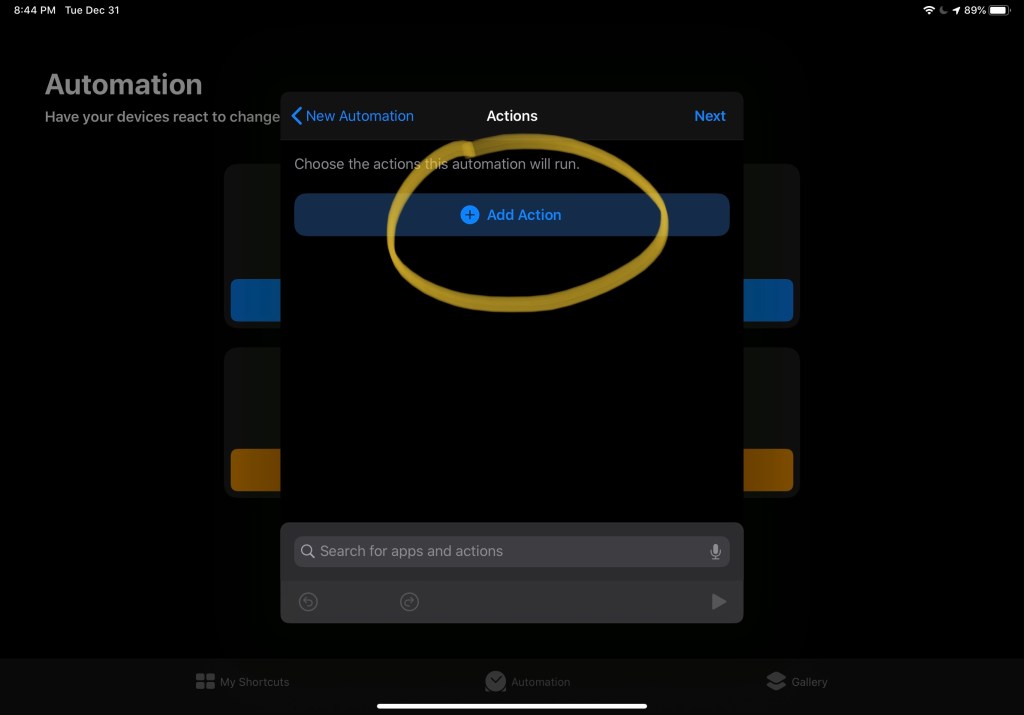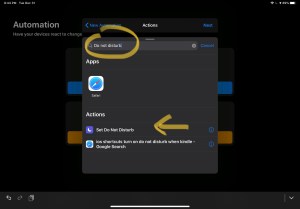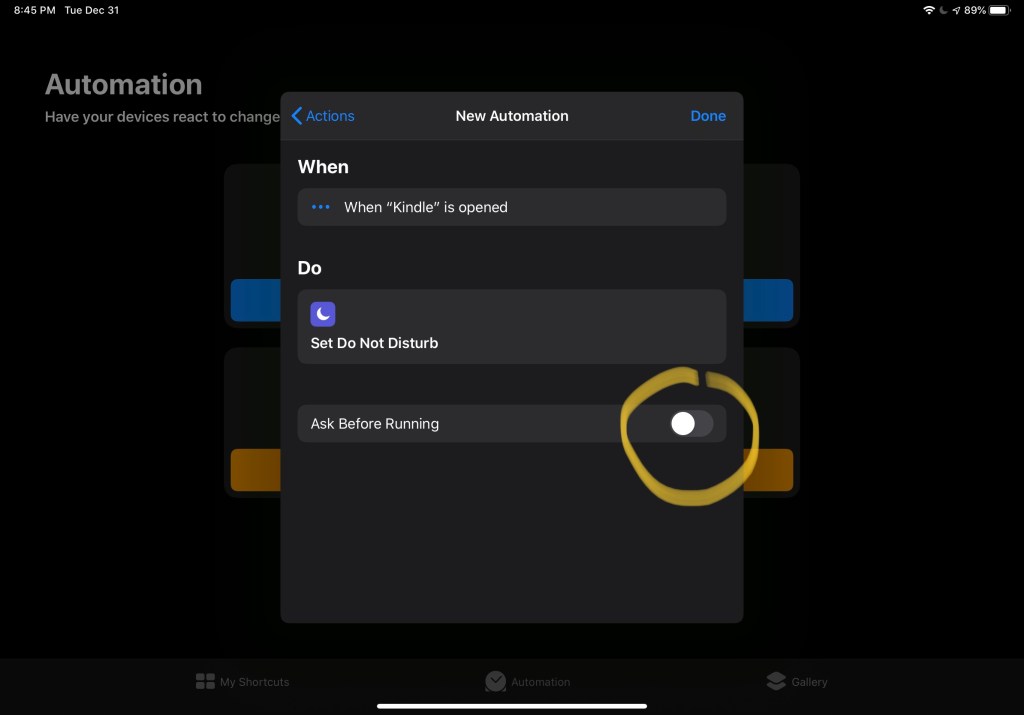
I’ve heard before that if you see a title ending in a question mark, the answer is most likely going to be “no”.
Unfortunately, I’m not going to breaking any traditions here.
Background: AWS announced today that they have added support for EC2 backups now in their backup service. The AWS backup service now has backup options for Amazon EBS volumes, Amazon Relational Database Service (RDS) databases, Amazon DynamoDB tables, Amazon Elastic File System(EFS), Amazon EC2 instances and AWS Storage Gateway volumes.
But if you’re expecting this to be like the backup/recovery solutions you’ve run on-prem, you’re in for a rude awakening. It’s not. This has the scent of a minimally-viable product, which I’m sure they’ll build on and make compelling one day, but that day isn’t today.
It’s VERY important that you read the fine print on how the backups occur on the different services covered, and more importantly how you restore, and at what granularity you’re restoring.
First- from a fundamental architectural perspective- backups are called “recovery points”. That’s an important distinction. We’ve seen the recovery point term co-habitate with “snapshot”. In fact, EBS “backups” are just that- snapshots.
So for EC2 and EBS-related backups (oops, “Recovery Points”), you’re simply restoring a snapshot into a NEW resource. Want to restore a single file or directory in an EC2 instance or in a filesystem on your EBS volume? Nope. All or nothing. Or, you’ll restore from the RP into a new resource, and copy the needed data back into your live instance. I’m sorry, that’s just not up to today’s expectations in backup and recovery.
What about EFS? Well, glad you asked. This is NOT a snapshot. There is ZERO CONSISTENCY in the “recovery point” for EFS, as the backup in this case doesn’t snapshot- it iterates through the files, and if you change a file DURING a backup, there is a 100% chance that your “recovery point” won’t be a “point” at all- so you could break dependencies in your data. Yet they still call the copy of this data a “restore point”. Give them props for doing incremental forever here, but most file backup solutions (when paired with enterprise NAS systems or even just Windows) know how to stun the filesystem and stream their backups from the stunned version, rather than the volatile “live” filesystem. Also, if you want to do a partial recovery, you cannot do it in-place- it goes to a new directory located at the root of your EFS.
The BIGGEST piece missing from the AWS Backup Service is something we’ve learned to take for granted from B/R solutions: CATALOG. You need to know what you want to restore AND where to find it in order to recover it. With EFS, this can get REALLY dicey. It’s really easy to choose the wrong data, perhaps it’s a good thing they don’t allow you to restore in place yet!
Look, I applaud AWS for paying some attention to data protection here. This does shine a light on the fact that AWS data storage architecture lends itself to many data silos that require a SPOG to manage effectively and compliantly. However, there is a (very short) list of OEM B/R and data management vendors that can do this effectively not just within AWS but across clouds, and still give you the content-aware granularity you need to execute your complex data retention and compliance strategies and keep you out of trouble.
So many organizations are rushing to the cloud, make sure that you’re paying adequate attention to your data protection and compliance as you go, you’ll find that while the cloud providers are absolutely amazing at providing a platform for application innovation and transformation, data governance, archive, and protection are not necessarily getting the same level of attention from them- it’s up to YOU to protect that data and your business.